
在西方国家还沉浸在圣诞假期的喜庆气氛中时,中国企业已经悄悄地放出了新年的大招,让海外同行措手不及,脑瓜子嗡嗡作响。
首先是宇树科技的机器狗视频,惊艳了全球网友,让人不禁惊呼:“还要啥波士顿动力?”
紧随其后,又一款国产大模型DeepSeek横空出世,甚至隐隐有做空英伟达的味道。到底是怎么回事?且听我细细道来。
开源、性能一流、技术牛逼、价格击穿地心
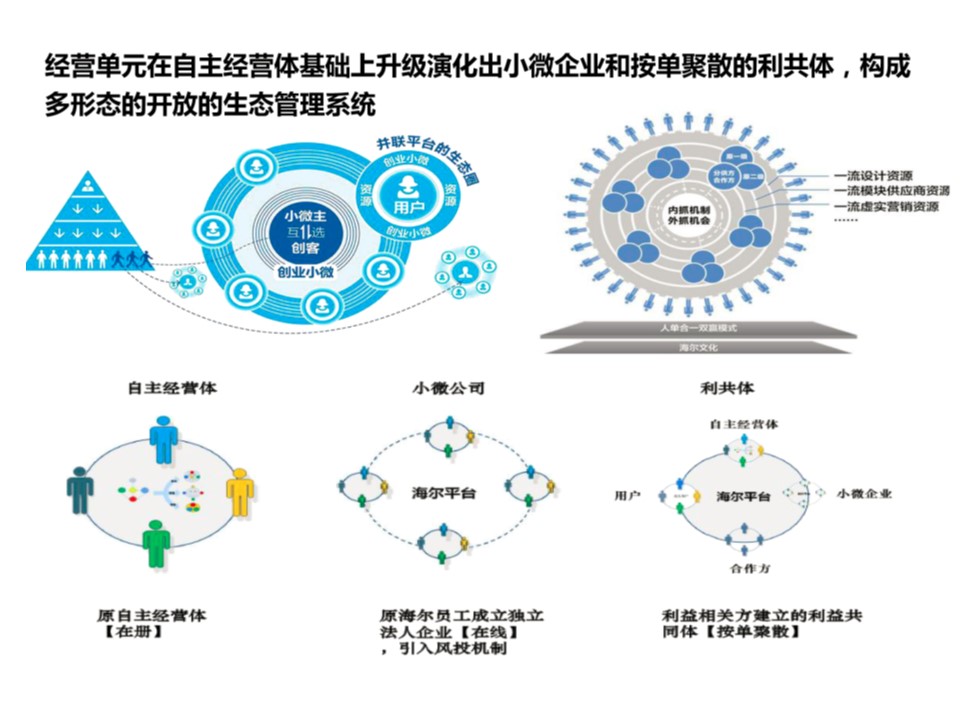
就在几天前,DeepSeek刚刚公布了最新版本V3。与大洋彼岸那个自称开源但越来越封闭的公司不同,DeepSeek-V3是一款真正的开源大模型。
开源并不是DeepSeek-V3最引人注目的标签。这款大模型还兼具以下三个特点:
- 性能国际一流
- 技术实力牛逼
- 价格击穿地心
这一套组合拳打得业内大模型厂商们措手不及,头晕目眩。
业内大牛点赞,奥特曼酸溜溜
V3一经发布,OpenAI创始成员Karpathy兴奋不已,甚至发出了灵魂拷问:“难道说大模型们压根不需要大规模显卡集群?”估计英伟达的黄仁勋看到这则消息,头发都要竖起来了。
同时,Meta的AI技术官也直呼DeepSeek的成果伟大。知名AI评测博主TimDettmers更是赞不绝口,表示DeepSeek的处理“优雅而细腻”。
当这些技术大牛对V3赞赏有加时,也有人坐不住了。比如奥特曼就阴阳怪气地说:“复制比较简单啦”,让人不免觉得他在内涵DeepSeek。
从量化投资跨界AI,深度求索的弯道超车
让人意外的是,做出这些成就的公司既不是什么科技巨头,也不是纯正的AI厂商。DeepSeek公司中文名叫“深度求索”,此前与AI领域并无任何关联。
就在大模型爆火之前,深度求索只是私募机构幻方量化的一个团队。而深度求索能够实现弯道超车,既有必然性,也有几分运气。
早在2019年,幻方量化就投资2亿元搭建了自研深度学习训练平台“萤火虫一号”。到了2021年,幻方量化已经斥巨资购买了万颗英伟达A100显卡,算力储备极其充足。
值得注意的是,当时大模型还没有火爆,万卡集群的概念也尚未出现。正是凭借这部分硬件储备,幻方量化才拿到了AI大模型的入场券,最终研发出了V3版本。
说到这里,可能有人会好奇:好好的一家量化投资公司,干嘛要跨界搞AI?
在接受采访时,深度求索CEO梁文锋表示,他们并不是看中了AI的前景,而是认为通用人工智能可能是下一个最难的事之一。对他们来说,这是一个“怎么做”的问题,而不是“为什么做”的问题。
正是抱着这样的决心和魄力,深度求索才创造了这次的大新闻。下面就来具体分析一下V3有哪些特别之处。
强悍的性能
从目前来看,在V3面前,开源模型几乎没有一款能打的。
去年年中,Meta推出的模型Llama3.1凭借其优异的性能和开源特性备受瞩目。然而在V3面前,Llama3.1全面落败。
至于那些大厂的闭源模型,比如GPT-4o、Claude3.5和Sonnet等,V3也能打得有来有回。
看到这里,你可能会觉得:“不就是追上了国际领先水平吗?至于这么吹嘘吗?”
真正的狠货还在后面。

极具性价比
大家都知道,现在的








发表评论